
前言
之前在学习go的时候,我写过一个爬虫,爬取电影网站的海报等信息,于是我就用go写了一个简单的下载器,基本上就是获取http中的返回的body,然后用文件保存下来数据即可。最近看到了这堆代码,发现在大文件的下载,效率很慢,因为大文件非常耗时,于是对代码进行了优化,并有了数倍下载性能的提升,于是写下了本次博客分享给大家。当然我们的下载器是支持百度云的文件下载,所以对于没有百度云会员的同学来说,可以说是个福音,因为使用本程序可以提升数倍下载效率。
理论
- 那么如何实现并发的下载一个文件呢?
当然就是将文件切割成不同的小文件,然后并发的下载这些小文件,然后写到最终的文件即可。
http的请求header头提供了一个range的参数。
range: bytes=0-2其中0-2表示需要返回文件的第【0】个位置到第【2】个位置的数据。 range参数是怎么工作的? 当服务器收到这个range参数时,如果当前的服务器支持range,那么会返回http code = 206 partial content状态码表示支持,并返回range对应的范围的文件数据。 如果服务器不支持range,那么服务器会返回200并返回整个文件。因为本次是并发下载,可能用户设置了并发下载的数量为20,那么如果此下载链接不支持range,那么需要强制将并发下载的数量改为1。 需要注意的是,如果服务器支持range,那么http 的response返回的content-Length并不是整个文件的大小,而是当前切分文件的大小。且response中会返回Content-Range字段,返回的结果为bytes 0-2/523231, 其中【0-2】表示当前返回的文件切分的范围,从文件的第0个开始,第2个结束。后面523231才表示整个文件的大小。 按照上面的原理,我用go实现了支持range的http server- 上面链接的代码中,可能有细心的小伙伴注意到,我这边设置了response的header字段
Content-Disposition为文件名,这个是干什么的? 因为有些下载地址并不是直接的文件url,而是通过附件的形式保存文件,此时服务器会将文件名设置到http的response的Content-Disposition字段,其中filename="filename.jpg"就是文件的真实名称。那么我们只要通过这个header就可以取到文件的真实文件名称以及格式了。 - 文件怎么分批写入?
首先,我们先创建一个和原文件一样的文件和大小(
os.Create && file.Truncate),然后通过文件大小除以并发的数得到每个并发需要下载多少大小的文件,然后开启http并携带文件的开始和结束的大小的range给服务端进行下载,最终得到数据进行写对应的开始的位置即可(file.WriteAt)
代码实现
- 设置配置
options结构体的字段都是可以配置的,所以我们需要在New函数中传递可变参数,如果只需要设置失败重试的次数,那么我们只要在type options struct { SaveName string `json:"save_name"` //保存文件名称 SavePath string `json:"save_path"` //保存的文件夹 ProxyHost string `json:"proxy_host"` //设置http代理 CustomHeader map[string]string `json:"custom_header"` //设置http的header Timeout int `json:"timeout"` //设置超时时间 DownloadRoutine int `json:"download_routine"` //下载的协程 BreakPoint bool `json:"break_point"` //是否需要支持断点续传 TryTimes int `json:"try_times"` //失败重试次数 StrategyWait bool `json:"strategy_wait"` //策略等待 } type Option func(*options) func SetTryTimes(name string) Option { return func(o *options) { o.SaveName = name } } func SetDownloadRoutine(num int) Option { return func(o *options) { o.DownloadRoutine = num } } .... func NewDownloader(urlString string, option ...Option) (*Downloader, error) { var op options if len(option) > 0 { for _, opt := range option { opt(&op) } } //..... }NewDownloader中传入SetTryTimes()即可,如果还有需要设置的参数,继续在后续中新增Set函数,比如设置下载并发的数量如下图所示//设置并发数、设置重试次数 down, err := NewDownloader(targetUrl, SetDownloadRoutine(20), SetTryTimes(200), ) //仅设置并发数 down, err := NewDownloader(targetUrl, SetDownloadRoutine(20), ) - 获取文件是否支持并发下载(使用header的range查看是否返回206)
首先我们需要发0-3个字节去检验当前的下载链接是否支持range下载,并把文件的大小、文件的名字获取到,如果不支持range下载,那么需要把并发下载的数量设置为1。如果
content-range中没有返回文件的大小,需要去content-length中获取文件的大小。func (a *Downloader) setDownloadFileInfo(header http.Header) { cdData := header.Get("Content-Disposition") if cdData != "" { var re = regexp.MustCompile(`(?m)filename="(.*)"`) list := re.FindAllStringSubmatch(cdData, 100) if len(list) > 0 && len(list[0]) >= 1 { a.setSaveName(list[0][1]) } } crData := header.Get("Content-Range") if crData != "" { var re = regexp.MustCompile(fmt.Sprintf(`%s\/(.*)`, getResponseHeaderRange())) list := re.FindAllStringSubmatch(crData, 100) if len(list) > 0 && len(list[0]) >= 1 { _n, _ := strconv.Atoi(list[0][1]) a.setFileSize(_n) } } if a.fileSize == 0 { clData := header.Get("Content-Length") if clData != "" { _n, _ := strconv.Atoi(clData) a.setFileSize(_n) } } } - 并发下载
使用文件的大小除以并发下载的数量,然后请求接口(带上range),接口返回需要判断下接口返回的status是否为206或者200,然后接受http的body,然后从文件的range的开始的offset写文件即可。
就这样一个使用go写的并发下载器就实现了func (a *Downloader) doMultiDownloadWithoutBreakPoint(ctx context.Context) error { if err := a.createFile(); err != nil { return err } defer a.fd.Close() childCtx, _ := context.WithCancel(ctx) var wg sync.WaitGroup wg.Add(a.option.DownloadRoutine) if a.option.StrategyWait { time.Sleep(3 * time.Second) } per := a.fileSize / a.option.DownloadRoutine for i := 0; i < a.option.DownloadRoutine; i++ { startId := i * per endId := (i+1)*per - 1 if i == (a.option.DownloadRoutine - 1) { endId = a.fileSize } go func(ctx context.Context, i, startId, endId int) { defer wg.Done() for j := 0; j < a.option.TryTimes; j++ { if a.option.StrategyWait { time.Sleep(time.Duration(utils.Rand(3, 10)) * time.Second) } if err := a.doHttpRequest(ctx, startId, endId); err != nil { log.Printf("gId:%d range:%d-%d error:%v try:%d", i, startId, endId, err, j) } else { log.Printf("\033[32m gId:%d range:%d-%d \033[0m", i, startId, endId) break } } if a.option.StrategyWait { time.Sleep(time.Duration(i)*time.Second) } }(childCtx, i, startId, endId) } wg.Wait() return nil } func (a *Downloader) doHttpRequest(ctx context.Context, startId, endId int) error { rangeStr := getHeaderRange(startId, endId) resp, err := a.prepareHTTPClient(ctx, a.Url, HTTPGet, rangeStr) if err != nil { return err } defer resp.Body.Close() if a.fd == nil { return ErrorFileIsError } if resp.StatusCode != http.StatusOK && resp.StatusCode != http.StatusPartialContent { return errors.New(fmt.Sprintf("startId %d- endId %d response status is not valid,now is %d", startId, endId, resp.StatusCode)) } result, _ := ioutil.ReadAll(resp.Body) _, err = a.fd.WriteAt(result, int64(startId)) return err }
可能你也曾经用过某种语言实现过上述的逻辑代码,但是你知道如果将你的下载器兼容百度云下载吗?func TestNewDownloader(t *testing.T) { text := "https://cdn.poizon.com/leap/A5CEF94C-5BA4-45F4-BB9F-8B7E7ADA02C2.mov_dgTLUAnsBO.mp4" down, err := NewDownloader(text, SetTimeout(222601), SetDownloadRoutine(4), ) if err != nil { log.Println(err) } else { err = down.SaveFile(context.Background()) if err != nil { fmt.Println(err) } else { fmt.Println(down.option.SaveName) } } }支持百度云
理论上只要是支持浏览器下载,并且下载链接支持range,那么本程序都支持。
百度云由于某些因素,每次访问range后都会大概率触发接口403(下载大文件问题突出),然后等几秒后再次请求就会正常,所以利用这个机制,我们可以在代码中加入重试机制(SetTryTimes(100)),加入等待(SetStrategyWait(true)),就可以完美的支持百度云的下载。
先看疗效
- 下载小文件 百度云点击直接下载,预计需要8分钟
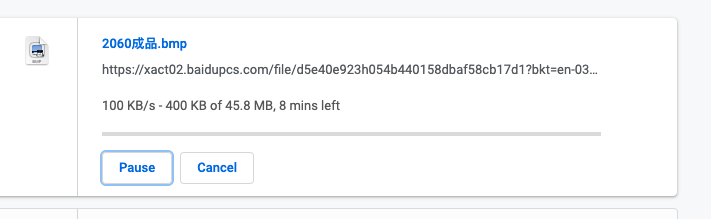
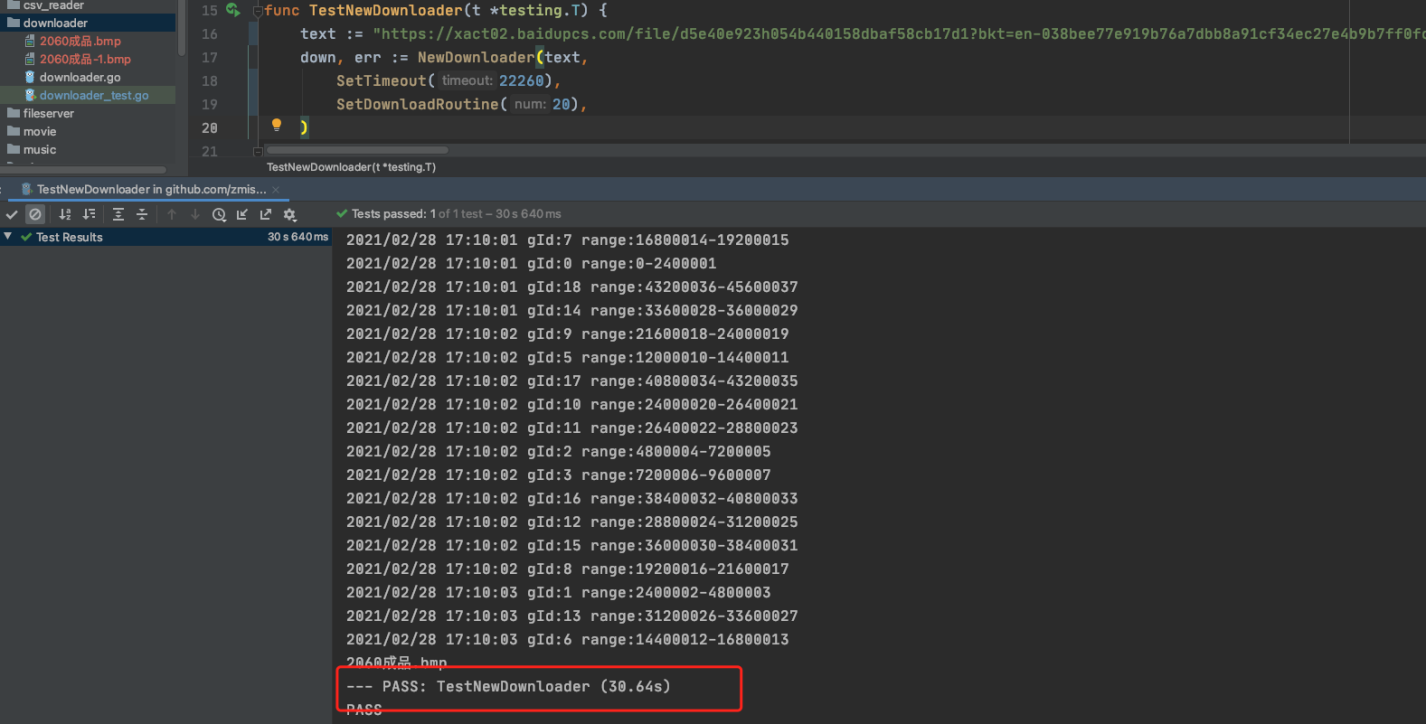
使用本代码,开了20个并发,30s完成下载(小文件开启并发下载数量不会触发403)
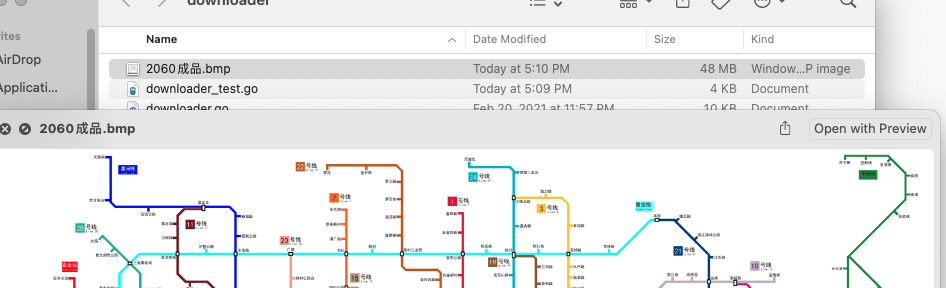
下载后文件正常打开
- 下载大文件 百度云下载376M的视频,非会员需要50+分钟

本次需要13.3分钟
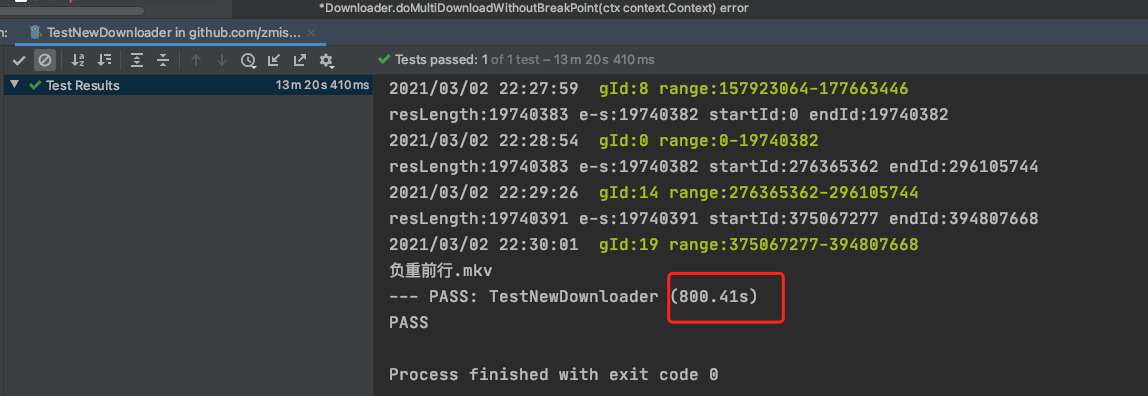
耗费的时间主要在请求百度云会大概率触发下载接口403,所以我这边每几秒都会去重试 //TODO 由于我这边开的协程,协程可能在同一时间内并发n个请求导致403的时间延长,这里的代码如果优化成每3秒只有一个协程去重试,那么下载的速度就会更快。 获取百度云下载地址 我们知道,百度云比较坑,下载龟速,小文件可以直接下载,但是大文件还需要下载客户端下载。本节将介绍如何获取百度云的真实下载地址。
- 小文件获取下载链接 百度云盘直接点击下载按钮
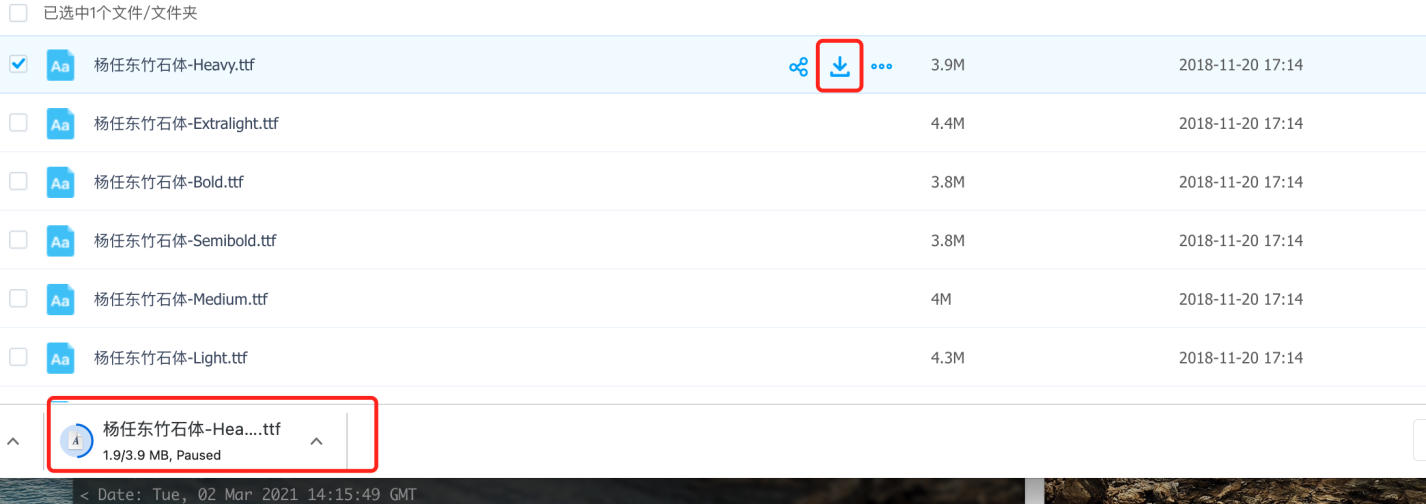
打开chrome的下载列表,可以获取到下载链接,
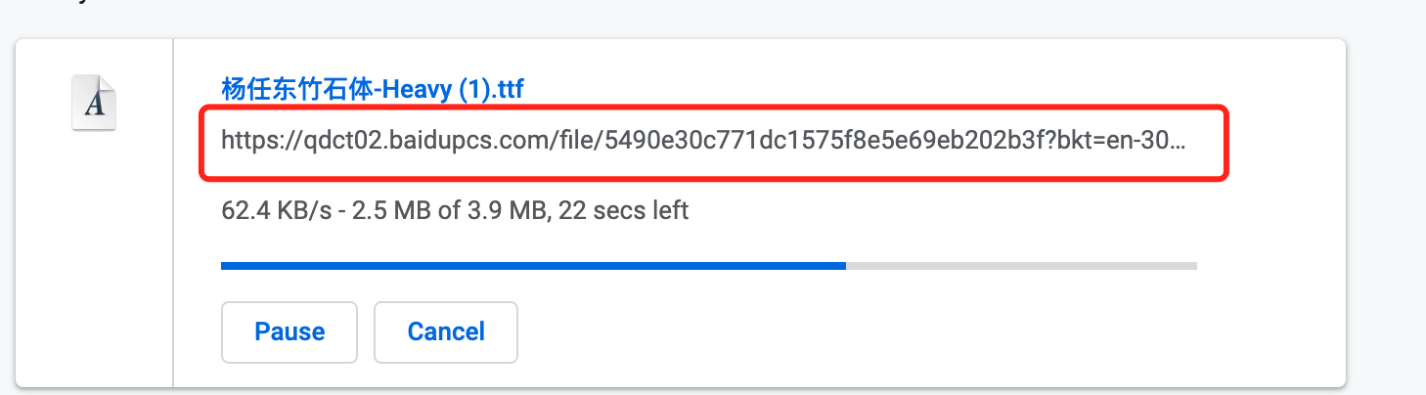
链接如:"https://qdall01.baidupcs.com/file/4bc5....... "
2. 获取大文件下载地址
我们知道,百度云由于限制,只能使用百度云盘客户端下载大文件,那么我们怎么获取大文件的下载地址呢?
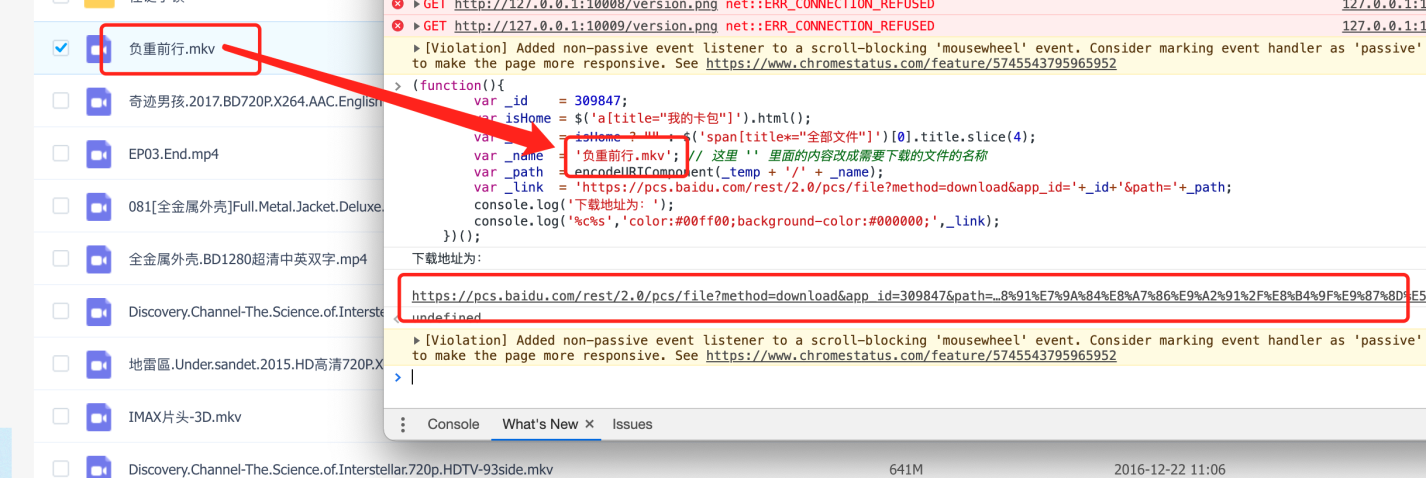
打开百度云,然后选择你要下载的文件,先获取文件名字(本次下载的是一个名为”负重前行.mkv“的视频),然后将文件名放入下面js的“_name”的变量中,然后在console中回车,js代码如下。
(function(){
var _id = 309847;
var isHome = $('a[title="我的卡包"]').html();
var _temp = isHome ? "" : $('span[title*="全部文件"]')[0].title.slice(4);
var _name = '负重前行.mkv'; // 这里 '' 里面的内容改成需要下载的文件的名称
var _path = encodeURIComponent(_temp + '/' + _name);
var _link = 'https://pcs.baidu.com/rest/2.0/pcs/file?method=download&app_id='+_id+'&path='+_path;
console.log('下载地址为:');
console.log('%c%s','color:#00ff00;background-color:#000000;',_link);
})();此时console中会有一个下载地址,点击打开,此时chrome会一个下载这个文件,打开chrome的下载列表
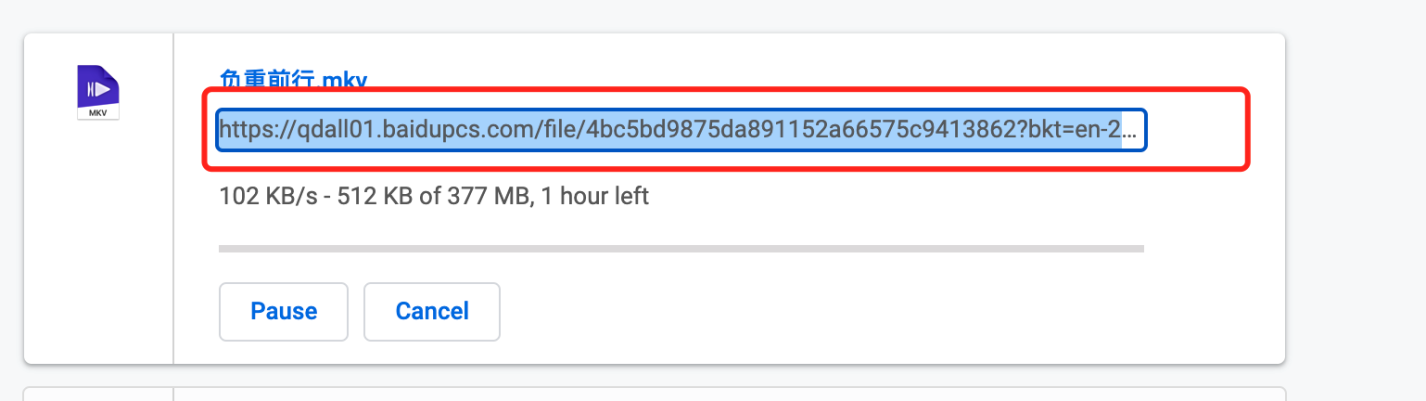
右键复制链接地址,然后将上面的链接"https://qdall01.baidupcs.com/file/4bc5....... "复制到本程序。使用本程序 将上面复制好的下载链接地址,替换下面代码中text的值。 //text中换成你的下载链接
down, err := NewDownloader(text,
SetTimeout(222601),//设置超时
SetDownloadRoutine(20),//设置并发数
SetStrategyWait(true),//设置策略等待
SetTryTimes(200),//设置尝试次数
)
if err != nil {
log.Println(err)
} else {
err = down.SaveFile(context.Background())
if err != nil {
fmt.Println(err)
} else {
fmt.Println(down.option.SaveName)
}
}然后执行本程序即可。 github地址 欢迎star